I find the concept of "Standard SQL" - referring to these magical ANSI/ISO/IEC/whatever documents that spec out how SQL is supposed to work - to be a fascinating subject. Lately I've been thinking about my personal observation that hardly anybody who works with SQL knows what's in "the standard" and what isn't.
I can't blame them, because these documents are not freely available to the world. Look below to see how much they cost to read on iso.org:

So unless you're a corporation with a big budget for this sort of thing, like Oracle or Snowflake, or perhaps a university, you're probably not going to justify purchasing those docs. I, as an individual SQL geek, have thought about purchasing these docs to read over, with the hopes of taking my SQL knowledge to a higher level, or at least to a place I haven't been able to explore before. That is, until I learned that I couldn't simply shell out ~$300 once and get it all. There are ABOUT A DOZEN docs at that price! And then I'd potentially have to buy all the incremental updates as well. So clearly they aren't intended for the curious individual to purchase.
There are, however, some third-party sources of information that do a good job of parsing out which syntaxes and features are and are not in standard SQL, and which iterations. Markus Winand's fantastic web site modern-sql.com comes to mind. Wikipedia isn't a bad reference either, just to get a high-level overview of which features are in which version of the standard (for example: https://en.wikipedia.org/wiki/SQL:1999)
But what I've noticed over the years is that many folks who work with SQL will meet a particular SQL engine's special feature with suspicion because it's non-standard. Or at least, it's not standard...in their opinion! In other words, they might say something like, "I don't want to use some vendor-specific oddity, because if I need to switch engines down the line, that will make life difficult."
My thoughts on this kind of remark are as follows:
1. There actually is no full implementation of standard SQL!
Here is a brilliantly simple exchange on X (formerly Twitter) that I saw a few years ago:
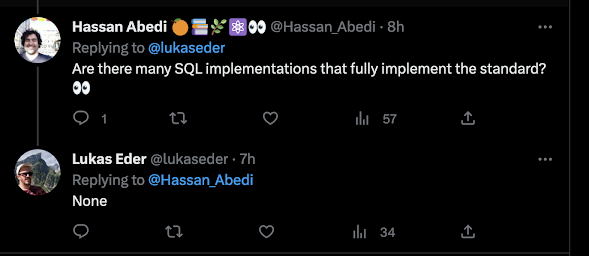
Lukas Eder, who made the one-word reply, is the creator of the SQL framework for JVM-based languages called jOOQ. jOOQ's list of supported DBMSs can be found here.
I mention that list because if someone who has painstakingly dealt with the
ins and outs of SQL syntax between ALL those different dialects can
confidently state that NONE of the implementations is complete, we
should probably take his word for it.
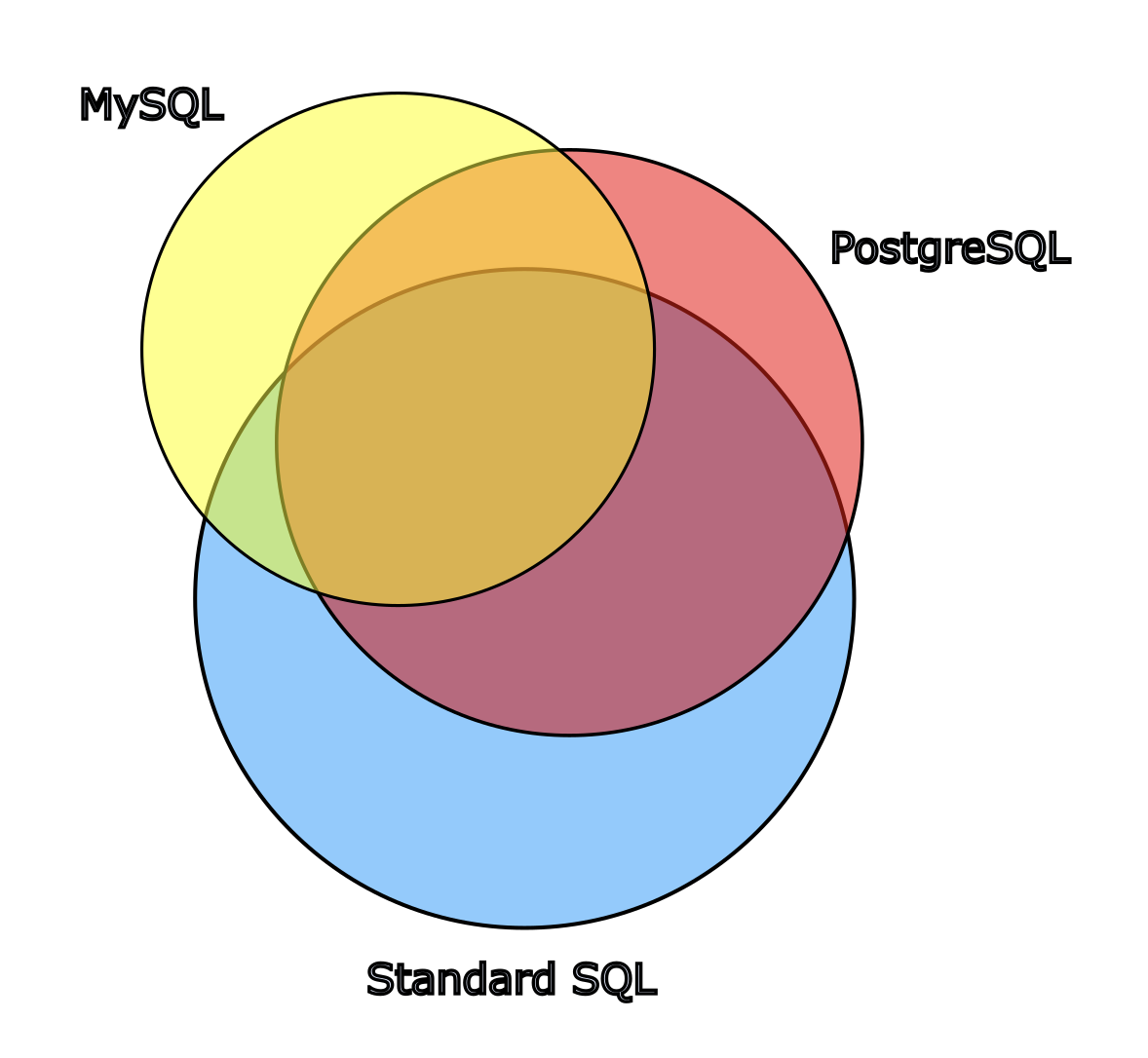
Additionally, loosely speaking, pretty much all the implementations add their own inventions. And consider that for any given standard SQL feature, it may or may not exist in both SQL Engine ABC and SQL Engine XYZ. The overlap with standard SQL tends to be much looser than many people realize. So if I were to draw a Venn diagram to depict standard SQL and various implementations thereof, in which area on the diagram represents features and syntaxes, it might look something like the following (I'm constraining myself to only standard, Postgres and MySQL for simplicity's sake):
-
Disclaimer: the above diagram is not to scale in any meaningful way; nor
did I attempt to take on the Herculean task of methodically evaluating
feature sets in a technically accurate manner and sizing these circles
accordingly. In other words this diagram isn't "real"; I just made it to
illustrate how I personally conceptualize the fact that all
implementations partially and loosely overlap with standard SQL as well
as each other!
So with the above diagram in mind, say you're using Postgres. If you limit yourself to the Postgres features that overlap with standard SQL only, you're omitting a large chunk of what Postgres has to offer!
2. In my experience, switching between SQL engines is a rare event.
If you do have a need to interact with multiple engines as a requirement, you would probably want a tool to handle the SQL conversions, or generation, for you anyway, perhaps jOOQ, just to name one. If you don't have that requirement and you prefer writing SQL by hand, and the rare need to pivot from one DBMS to another does occur, then you would need a concerted effort to convert queries anyway (involving lots of testing).
3. Much of the time, in my experience, these claims of "that thing is not standard SQL" are just plain wrong!
I recently saw a post on LinkedIn, in which a poster was excited to share his recently acquired knowledge about the handy IS DISTINCT FROM syntax in Snowflake. Another user chimed in to say he didn't like that syntax, because it's non-standard. And yet here it is, being all standardy: https://modern-sql.com/caniuse/is-distinct-from.
.png)
I've seen this same kind of remark many, many times in SQL discussions over the years! It feels like many folks come up with a "pseudo-standard" model of what they think is standard in their head, based on which features and syntaxes they commonly see. They don't actually do their due diligence in determining what is and what isn't part of standard SQL, which again, I can't blame them too much for, since this is hard to do. (I've made this very error myself, even.) Instead, if they haven't seen some particular syntax too often, or it isn't widespread, they assume it is not standard SQL. Which brings me to my next point...
4. They are probably already using non-standard SQL features all the time anyway!
But before I elaborate on this point...
RANDOM POP QUIZ TIME:
Your query is returning a million rows, but you only want the first 10 rows to be returned. With which syntax can you modify your query to accomplish this, if you want to conform to standard SQL syntax only?
A) FETCH FIRST 10 ROWS ONLY
B) LIMIT 10
C) TOP 10
D) ROWNUM <= 10
I asked this question on my company's Slack server, and B) LIMIT 10, was the most popular response by far. But that's incorrect! LIMIT is common for SQL engines to support - MySQL supports it, as does Postgres and many others - but it is NOT mentioned in any of those crazy ANSI/ISO/etc. standard SQL docs! The correct answer is actually A) FETCH FIRST 10 ROWS ONLY
It just goes to show how obscure it is to know which syntax and features are part of standard SQL and which are not.
A few more examples of non-standard but common syntax:
- identifier quoting using backticks (e.g. `my_table`)
- identifier quoting using brackets (e.g. [my_table])
- string literal quoting with double quotes (e.g. WHERE NAME = "Mark")
- commonly used functions like DATEDIFF() and NOW()
- AUTO_INCREMENT (e.g. creating a column defined as ID INT AUTO_INCREMENT PRIMARY KEY) and SERIAL (the older way to accomplish this in Postgres)
- OFFSET (e.g. OFFSET 1000 LIMIT 10)
- CREATE MATERIALIZED VIEW (materialized views are not part of standard SQL)
5. "Standard" doesn't necessary mean "common" or "widespread."
Sometimes nonstandard syntaxes/features do have widespread adoption. Again, see LIMIT. So there's almost an "not truly standard but commonplace" set of syntaxes/features. Another example: I've been seeing the useful QUALIFY syntax more and more lately, particularly in analytic SQL engines, which has to do with filtering results of window functions more elegantly. Snowflake, BigQuery, Redshift and several others support QUALIFY. But is it standard? Nope!
6. Two implementations of one standard feature could have very different under-the-hood workings or options.
For some statements, such as CREATE INDEX, the basic syntax is standard but the options available to the statement may vary quite a bit per implementation. And those options drive what goes under the hood of the engine, which can be very different. Consider that Postgres features binary range (brin) indexes, but MySQL does not. So how do we even account for this fact in the above Venn diagram? Is it a three-way intersection (MySQL + Postgres + Standard SQL all include CREATE INDEX)? Is it a partial overlap? It's complicated.
In the case of CREATE MATERIALIZED VIEW, both Oracle and Postgres have this statement and the kind of database object, a materialized view, that can be created and used. But an Oracle Materialized View is much more robust and powerful than a Postgres materialized view (see this past post of mine for reference). MySQL does not have materialized views at all. Standard SQL does not even mention materialized views. So do the Postgres and Oracle circles in the Venn diagrams overlap for the area representing materialized views? It's complicated. (At least we know MySQL and Standard SQL would not!)
Another tricky case: two DBMSs have completely implemented a Standard SQL feature according to its spec, but they behave very differently! <TODO: expand on this>
7. Some Standard SQL features are considered "optional":
Fun fact:
Did you know that standard SQL:99 says you can access Java methods directly in the database server? It's called SQL/JRT and it is designated as "optional." So, if DBMS x supports the optional SQL/JRT and DBMS y does not, is x the more standard-compliant DBMS? I don't know the answer!
Oracle Database has a whole JVM built into the server that you need to allocate resources for, such as memory, just to support what it calls Java Stored Procedures. Are these Java Stored Procedures a standard-compliant version of SQL/JRT? I don't know, but it certainly covers similar ground at the very least.
What if this standard feature is generally considered a "bad thing"? I asked some coworkers for their opinions on the subject of SQL/JRT and one said: "It was a big hype at the beginning of century. It quickly faded because DB server is one of the most expensive types of app server especially when coupled with Oracle licenses."
So you could argue that in this case, this particular standard feature is optional, and arguably a bad thing (not sure I agree, but one can make a valid case, as my coworker did). So maybe we wouldn't count a DBMS lacking this feature to be "less standard complaint." I mean, I guess they're orthogonal concepts? (standard vs. "good") And the latter is subjective. Just talking out loud. :)
At the risk of belaboring the point, there's also PL/Java for Postgres. I'll just drop the link and move on, because at this point, my head is spinning. It's a complicated subject!
Closing
So to wrap up this post, in my view, usually you shouldn't even worry about what's in standard SQL! Use what works best for your DBMS/SQL Engine of choice. Don't use your DBMS in a lowest common denominator manner - use it to its fullest capacity! See the Venn diagram above. You should use the full circle for your DBMS, not just its intersection with "Standard SQL."
Avoid walking on eggshells worrying about it, continuously looking up what actually is and isn't in standard SQL in documents you probably don't have access to. It's not worth it in my opinion.
I personally make some exceptions on this point: I care when standard SQL dictates a particular syntax or feature should exist, and it's a good and sensible thing. Then the implementation, while supporting the standard syntax, also offers an alternative that deviates from the standard one for little to no good reason, or perhaps for legacy reasons. Then I usually push for use of the standard version.
For example, MySQL lets you quote string literals in single or double quotes by default. In other words I can run:
SELECT * FROM EMPLOYEE WHERE NAME = 'Mark'
or
SELECT * FROM EMPLOYEE WHERE NAME = "Mark"
Both seem to run just fine. But the double quotes buy me nothing in this situation. Plus whether this query even works within the scope of a MySQL query is contingent on whether SQL_MODE is set to ANSI_QUOTES. If enabled, the double quotes are not allowed to be used for a string literal -- your query would throw an error. So in my view, stick with the single quotes as standard SQL dictates. Using single quotes also provides an added bonus: the aforementioned "what if I want to switch engines?" compatibility. Even though I'm against worrying about that too much, it comes free in this case.
OK, that's about it. Let me leave you with a quote from my buddy Kevin, a fellow engineer with close to three decades of experience now, who I spoke to about this subject: "Ultimately, it makes no difference [whether or not a feature is standard], outside trying to prove a point in an argument."



.png)